前言:XBRL 的全球化與在地化挑戰
在數位時代,財務報告的標準化與互通性成為國際金融市場的重要基石。XBRL(eXtensible Business Reporting Language)作為一種基於 XML 的財務資訊交換標準,已被全球超過 50 個國家採用。然而,各國在導入 XBRL 時,都需面對如何在遵循國際標準的同時,適應本地會計準則與實務需求的挑戰。
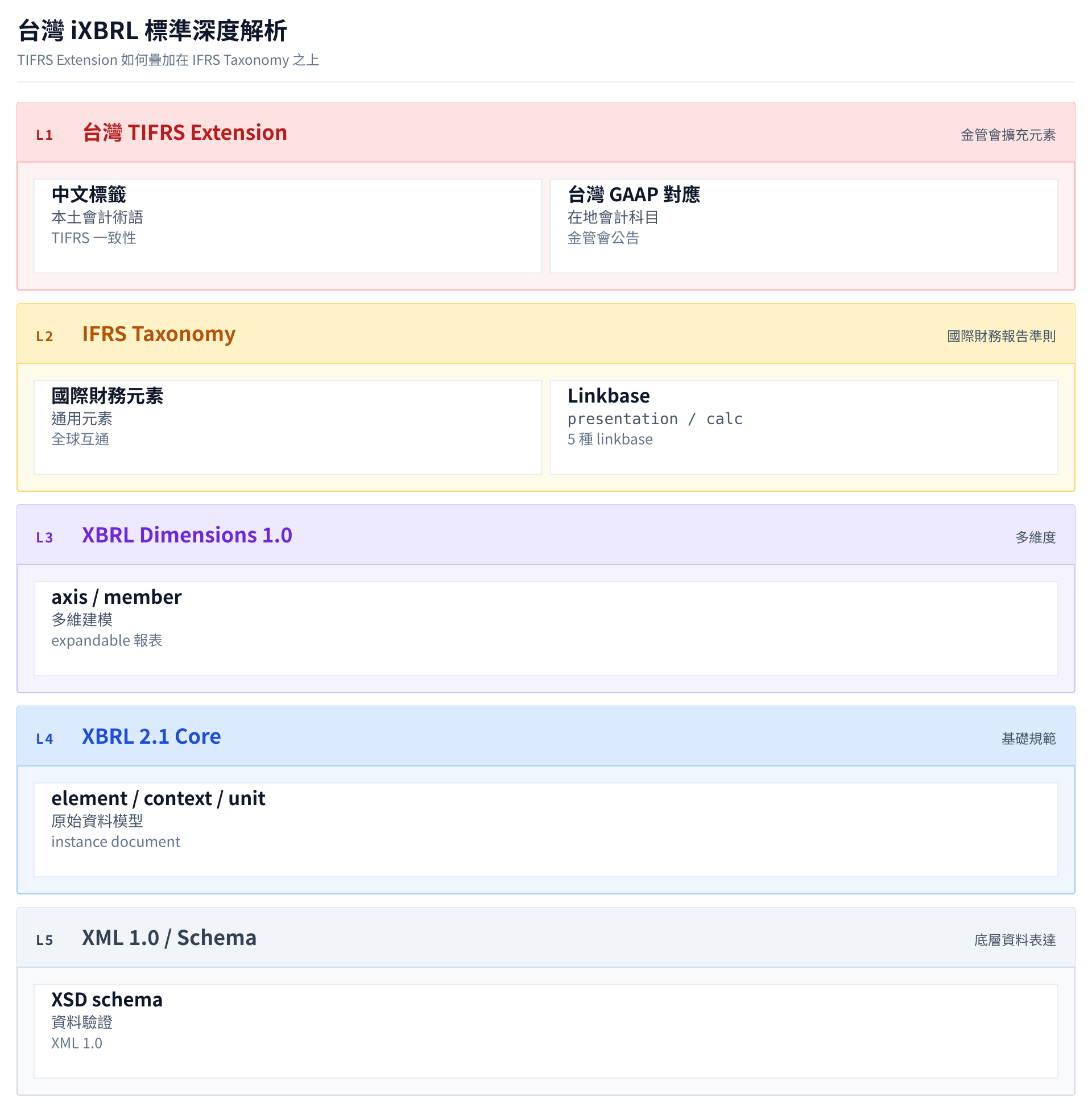
台灣證券交易所自 2018 年起全面實施 iXBRL(Inline XBRL)格式財報申報,建立了基於國際財務報導準則(IFRS)但具有台灣特色的 TIFRS(Taiwan International Financial Reporting Standards)分類標準。對於開發財報處理系統的技術人員而言,深入理解 TIFRS 與國際標準的差異,是確保系統正確性與穩定性的關鍵。
XBRL 國際標準架構
在探討台灣特色之前,我們先了解 XBRL 的國際標準架構。
核心規格層次
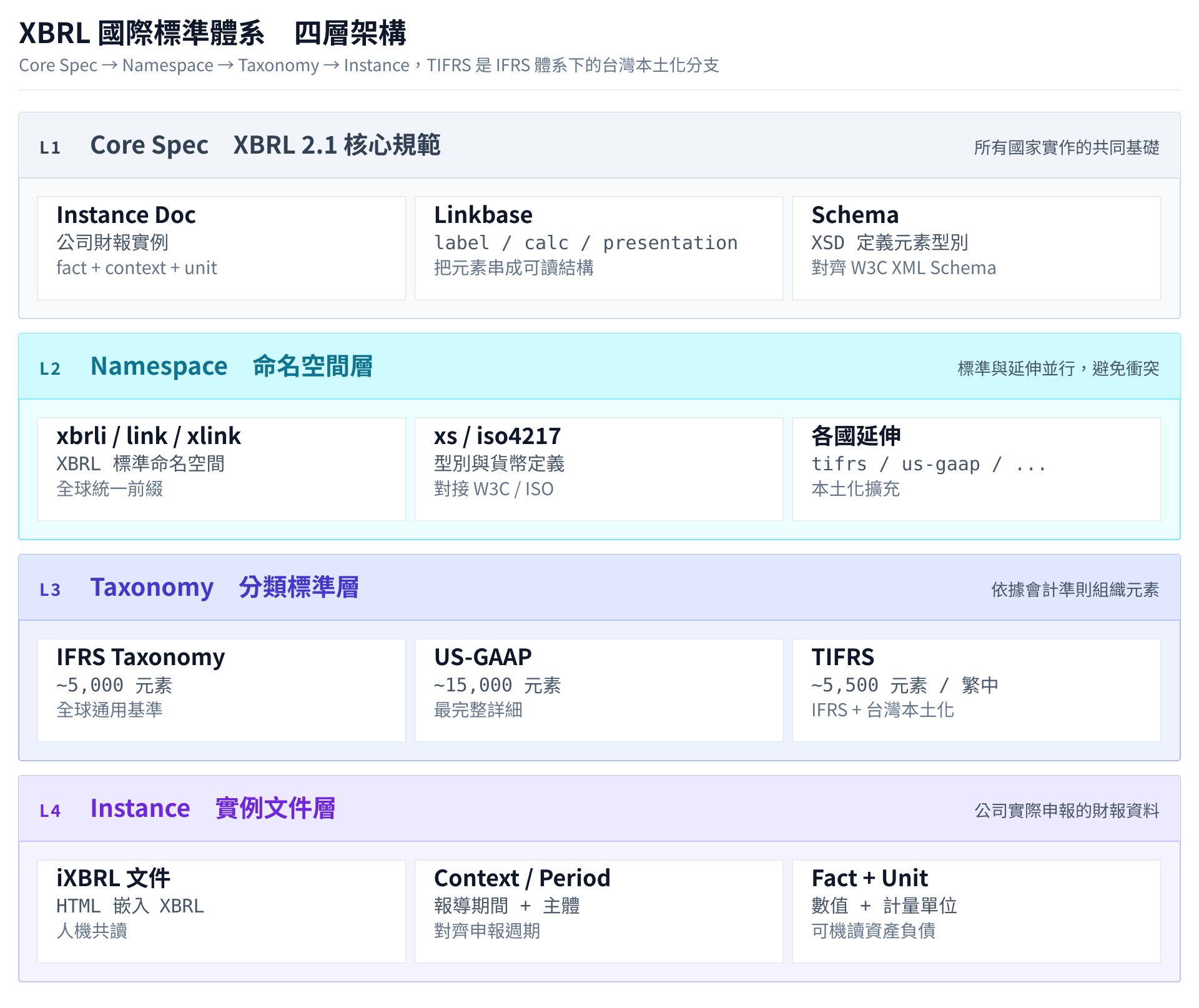
XBRL 2.1 核心元素
XBRL 2.1 規範定義了基礎架構,所有國家的實作都必須遵循:
基本命名空間
| 前綴 | 命名空間 URI | 用途 |
|---|---|---|
| xbrli | http://www.xbrl.org/2003/instance | XBRL 實例文件 |
| link | http://www.xbrl.org/2003/linkbase | 連結基礎 |
| xlink | http://www.w3.org/1999/xlink | XML 連結 |
| xs | http://www.w3.org/2001/XMLSchema | XML Schema |
| iso4217 | http://www.xbrl.org/2003/iso4217 | 貨幣代碼 |
文件結構範例
<?xml version="1.0" encoding="UTF-8"?>
<xbrli:xbrl
xmlns:xbrli="http://www.xbrl.org/2003/instance"
xmlns:link="http://www.xbrl.org/2003/linkbase"
xmlns:xlink="http://www.w3.org/1999/xlink"
xmlns:iso4217="http://www.xbrl.org/2003/iso4217">
<!-- Schema 參照 -->
<link:schemaRef
xlink:type="simple"
xlink:href="http://example.com/taxonomy.xsd" />
<!-- Context 定義 -->
<xbrli:context id="Current_AsOf">
<xbrli:entity>
<xbrli:identifier scheme="http://example.com">Company001</xbrli:identifier>
</xbrli:entity>
<xbrli:period>
<xbrli:instant>2024-12-31</xbrli:instant>
</xbrli:period>
</xbrli:context>
<!-- Unit 定義 -->
<xbrli:unit id="USD">
<xbrli:measure>iso4217:USD</xbrli:measure>
</xbrli:unit>
<!-- Fact 數據 -->
<ifrs-full:Assets contextRef="Current_AsOf" unitRef="USD" decimals="-3">
1500000000
</ifrs-full:Assets>
</xbrli:xbrl>國際主要分類標準
各標準特色比較
| 標準 | 基礎準則 | 元素數量 | 語言 | 特色 |
|---|---|---|---|---|
| IFRS | 國際會計準則 | ~5,000 | 英文為主 | 全球通用 |
| US-GAAP | 美國會計準則 | ~15,000 | 英文 | 最詳細完整 |
| JP-GAAP | 日本會計準則 | ~3,500 | 日文/英文 | 保守主義 |
| CN-GAAP | 中國會計準則 | ~4,000 | 簡體中文 | 趨同 IFRS |
| TIFRS | 等同 IFRS | ~5,500 | 繁體中文 | IFRS + 本土化 |
台灣 TIFRS 標準深度解析
命名空間體系
TIFRS 建立了獨立的命名空間體系,與國際 IFRS 並行但不相同。
國際 IFRS 命名空間結構
<!-- IFRS 標準命名空間 -->
xmlns:ifrs="http://xbrl.ifrs.org/taxonomy/2023-03-23/ifrs"
xmlns:ifrs-full="http://xbrl.ifrs.org/taxonomy/2023-03-23/ifrs-full"台灣 TIFRS 命名空間結構
<!-- TIFRS 基礎命名空間 -->
xmlns:tifrs="http://www.xbrl.org/tw/fr/tifrs/2022-01-01"
<!-- TIFRS 分支命名空間 -->
xmlns:tifrs-bsta="http://www.xbrl.org/tw/fr/tifrs/bsta/2022-01-01" <!-- 資產負債表 -->
xmlns:tifrs-cor="http://www.xbrl.org/tw/fr/tifrs/cor/2022-01-01" <!-- 核心概念 -->
xmlns:tifrs-pfs="http://www.xbrl.org/tw/fr/tifrs/pfs/2022-01-01" <!-- 損益表 -->
xmlns:tifrs-cfs="http://www.xbrl.org/tw/fr/tifrs/cfs/2022-01-01" <!-- 現金流量表 -->
xmlns:tifrs-sce="http://www.xbrl.org/tw/fr/tifrs/sce/2022-01-01" <!-- 權益變動表 -->命名空間架構比較
實體識別碼(Entity Identifier)差異
國際標準做法
<xbrli:entity>
<xbrli:identifier scheme="http://www.sec.gov/CIK">0000012345</xbrli:identifier>
</xbrli:entity>台灣 TIFRS 做法
<xbrli:entity>
<xbrli:identifier scheme="公開資訊觀測站">2330</xbrli:identifier>
</xbrli:entity>台灣使用證券代號(Stock Code)作為主要識別方式,與國際上常用的 LEI(Legal Entity Identifier)或 CIK(Central Index Key)不同。
會計科目對應與差異
雖然 TIFRS 基本上等同於 IFRS,但在具體科目命名和分類上存在差異。
資產負債表科目對照
台灣特有科目範例
<!-- 台灣特有:預收款項(在流動負債中) -->
<tifrs-bsta:AdvanceReceipts
contextRef="Current_AsOf"
unitRef="TWD"
decimals="-3">
1500000
</tifrs-bsta:AdvanceReceipts>
<!-- 台灣特有:存出保證金 -->
<tifrs-bsta:RefundableDeposits
contextRef="Current_AsOf"
unitRef="TWD"
decimals="-3">
850000
</tifrs-bsta:RefundableDeposits>
<!-- 台灣特有:遞延所得稅負債 - 非流動 -->
<tifrs-bsta:DeferredTaxLiabilitiesNoncurrent
contextRef="Current_AsOf"
unitRef="TWD"
decimals="-3">
2300000
</tifrs-bsta:DeferredTaxLiabilitiesNoncurrent>語言標籤系統
TIFRS 最顯著的特色是完整的繁體中文標籤系統。
IFRS 標籤結構
<link:label
xlink:type="resource"
xlink:label="ifrs-full_Assets_label"
xml:lang="en">
Assets
</link:label>TIFRS 雙語標籤結構
<!-- 繁體中文標籤 -->
<link:label
xlink:type="resource"
xlink:label="tifrs-bsta_Assets_label"
xml:lang="zh-TW">
資產總計
</link:label>
<!-- 英文標籤 -->
<link:label
xlink:type="resource"
xlink:label="tifrs-bsta_Assets_label"
xml:lang="en">
Assets
</link:label>程式化提取標籤
def get_element_label(element, preferred_lang='zh-TW'):
"""
取得元素的標籤,優先使用指定語言
Args:
element: XBRL 元素
preferred_lang: 偏好語言('zh-TW' 或 'en')
Returns:
str: 元素標籤
"""
# 嘗試取得偏好語言標籤
labels = element.label(lang=preferred_lang, labelRole='http://www.xbrl.org/2003/role/label')
if labels:
return labels
# 降級到英文標籤
labels = element.label(lang='en', labelRole='http://www.xbrl.org/2003/role/label')
if labels:
return labels
# 最後使用元素本地名稱
return element.qname.localName技術實作關鍵差異
文件結構完整範例
典型 TIFRS iXBRL 文件結構
<?xml version="1.0" encoding="UTF-8"?>
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:xbrli="http://www.xbrl.org/2003/instance"
xmlns:link="http://www.xbrl.org/2003/linkbase"
xmlns:xlink="http://www.w3.org/1999/xlink"
xmlns:iso4217="http://www.xbrl.org/2003/iso4217"
xmlns:tifrs-bsta="http://www.xbrl.org/tw/fr/tifrs/bsta/2022-01-01"
xmlns:tifrs-cor="http://www.xbrl.org/tw/fr/tifrs/cor/2022-01-01">
<head>
<meta charset="UTF-8"/>
<title>台灣積體電路製造股份有限公司 - 合併資產負債表</title>
<!-- Schema 參照 -->
<link:schemaRef
xlink:type="simple"
xlink:href="http://www.xbrl.org/tw/fr/tifrs/2022-01-01/tifrs-2022-01-01.xsd"/>
</head>
<body>
<!-- Hidden XBRL Contexts -->
<div style="display:none">
<!-- 期間定義 -->
<xbrli:context id="CurrentYearEnd">
<xbrli:entity>
<xbrli:identifier scheme="公開資訊觀測站">2330</xbrli:identifier>
</xbrli:entity>
<xbrli:period>
<xbrli:instant>2024-12-31</xbrli:instant>
</xbrli:period>
</xbrli:context>
<xbrli:context id="CurrentYearDuration">
<xbrli:entity>
<xbrli:identifier scheme="公開資訊觀測站">2330</xbrli:identifier>
</xbrli:entity>
<xbrli:period>
<xbrli:startDate>2024-01-01</xbrli:startDate>
<xbrli:endDate>2024-12-31</xbrli:endDate>
</xbrli:period>
</xbrli:context>
<!-- 貨幣單位 -->
<xbrli:unit id="TWD">
<xbrli:measure>iso4217:TWD</xbrli:measure>
</xbrli:unit>
<xbrli:unit id="shares">
<xbrli:measure>xbrli:shares</xbrli:measure>
</xbrli:unit>
</div>
<!-- 可見的財務報表內容 -->
<table>
<tr>
<td>資產總計</td>
<td>
<ix:nonFraction
name="tifrs-bsta:Assets"
contextRef="CurrentYearEnd"
unitRef="TWD"
decimals="-3"
format="ixt:num-dot-decimal">
3,500,000,000
</ix:nonFraction>
</td>
</tr>
</table>
</body>
</html>日期與期間處理
台灣財報期間標記方式
<!-- 第一季 -->
<xbrli:context id="2024Q1">
<xbrli:entity>
<xbrli:identifier scheme="公開資訊觀測站">2330</xbrli:identifier>
</xbrli:entity>
<xbrli:period>
<xbrli:startDate>2024-01-01</xbrli:startDate>
<xbrli:endDate>2024-03-31</xbrli:endDate>
</xbrli:period>
<xbrli:scenario>
<tifrs-cor:PeriodTypeAxis>
<tifrs-cor:FirstQuarter/>
</tifrs-cor:PeriodTypeAxis>
</xbrli:scenario>
</xbrli:context>Python 期間處理工具
from datetime import datetime
from typing import Tuple
def parse_taiwan_period(context) -> Tuple[datetime, datetime, str]:
"""
解析台灣財報期間
Returns:
(開始日期, 結束日期, 期間類型)
"""
period = context.period
if period.isInstant:
date = period.instant
return date, date, "時點"
else:
start = period.startDate
end = period.endDate
# 判斷期間類型
months = (end.year - start.year) * 12 + (end.month - start.month)
if months == 3:
quarter = (end.month - 1) // 3 + 1
period_type = f"Q{quarter}"
elif months == 6:
period_type = "半年報"
elif months == 12:
period_type = "年報"
else:
period_type = f"{months}個月"
return start, end, period_type
# 使用範例
start, end, period_type = parse_taiwan_period(context)
print(f"期間:{start} 至 {end} ({period_type})")股本計算特殊性
台灣上市櫃公司多採用每股面額 10 元的標準,這在計算流通股數時需要特別處理。
台灣股本計算邏輯
實作範例
def calculate_taiwan_shares(financial_data: dict) -> dict:
"""
計算台灣公司的股數相關指標
Args:
financial_data: 包含權益總額、實收資本額等資訊
Returns:
計算結果字典
"""
# 台灣標準面額
PAR_VALUE = 10.0
# 方法一:從權益總額計算
equity = financial_data.get('equity', 0)
shares_from_equity = equity / PAR_VALUE if equity else 0
# 方法二:從實收資本額計算(更準確)
paid_in_capital = financial_data.get('paid_in_capital', 0)
shares_from_capital = paid_in_capital / PAR_VALUE if paid_in_capital else 0
# 優先使用實收資本額計算
outstanding_shares = shares_from_capital if paid_in_capital else shares_from_equity
# 計算每股指標
net_income = financial_data.get('net_income', 0)
eps = net_income / outstanding_shares if outstanding_shares else 0
book_value_per_share = equity / outstanding_shares if outstanding_shares else 0
return {
'outstanding_shares': outstanding_shares,
'eps': eps,
'book_value_per_share': book_value_per_share,
'par_value': PAR_VALUE
}
# 使用範例:台積電
tsmc_data = {
'equity': 3_000_000_000_000, # 3 兆元
'paid_in_capital': 2_593_000_000_000, # 2.593 兆元
'net_income': 980_000_000_000 # 9800 億元
}
result = calculate_taiwan_shares(tsmc_data)
print(f"流通股數: {result['outstanding_shares']:,.0f} 股")
print(f"每股盈餘: {result['eps']:.2f} 元")
print(f"每股淨值: {result['book_value_per_share']:.2f} 元")輸出
流通股數: 259,300,000,000 股
每股盈餘: 3.78 元
每股淨值: 11.57 元貨幣單位與尺度處理
TIFRS 貨幣單位標記
<!-- 新台幣單位 -->
<xbrli:unit id="TWD">
<xbrli:measure>iso4217:TWD</xbrli:measure>
</xbrli:unit>
<!-- 外幣單位 -->
<xbrli:unit id="USD">
<xbrli:measure>iso4217:USD</xbrli:measure>
</xbrli:unit>數值尺度標記
台灣財報常用「千元」、「百萬元」等尺度單位:
<!-- 使用 decimals 屬性表示精度 -->
<tifrs-bsta:Assets
contextRef="Current"
unitRef="TWD"
decimals="-3">
1500000
</tifrs-bsta:Assets>
<!-- 實際值:1500000 × 1000 = 1,500,000,000 元 -->尺度轉換工具
def normalize_taiwan_amount(value: float, decimals: int) -> float:
"""
根據 decimals 屬性正規化金額
Args:
value: XBRL 文件中的數值
decimals: decimals 屬性值
Returns:
正規化後的金額(單位:元)
"""
if decimals is None:
return value
# decimals 為負數時,表示精度到多少位
# decimals="-3" 表示千元
# decimals="-6" 表示百萬元
if decimals < 0:
multiplier = 10 ** abs(decimals)
return value * multiplier
else:
return value
# 範例
value_in_doc = 1500000 # 文件中的值
decimals = -3 # 千元
actual_value = normalize_taiwan_amount(value_in_doc, decimals)
print(f"文件值: {value_in_doc:,}")
print(f"實際值: {actual_value:,.0f} 元")
print(f"十億元: {actual_value / 1_000_000_000:.2f}")完整解析實作範例
使用 Arelle 解析 TIFRS 文件
Arelle 是最廣泛使用的開源 XBRL 處理器,原生支援 IFRS / US-GAAP / TIFRS。pip install arelle-release 即可使用,或從源碼編譯以掛載自訂 plugin。
最小可用骨架
from arelle import Cntlr
cntlr = Cntlr.Cntlr()
model = cntlr.modelManager.load("tsmc_2024q4.xbrl")
# 1) 公司識別(公開資訊觀測站 scheme)
for ctx in model.contexts.values():
if ctx.entityIdentifier and ctx.entityIdentifier[0] == "公開資訊觀測站":
print("Stock code:", ctx.entityIdentifier[1])
break
# 2) 抽取財務數據(含中文 label 與單位)
for fact in model.facts:
label = fact.concept.label(lang="zh-TW") or fact.concept.label(lang="en")
unit = fact.unit.measures[0][0].localName if fact.unit else None
print(f"{label}: {fact.value} unit={unit}")設計重點
decimals屬性正規化:負值代表「千元」、「百萬元」等放大倍數,計算前必須乘上10 ** abs(decimals),否則所有金額會少幾個數量級。- 多語言 label fallback:
concept.label(lang='zh-TW')取繁中標籤,缺則退回英文,避免 KeyError。 context.isInstant區分時點與期間:True 是資產負債表項目(期末快照),False 是損益表項目(期間累計)。- 計算鏈路驗證:呼叫 Arelle 的
compileCalc()確認資產負債表恆等式(資產 = 負債 + 權益),常用於 QA。
完整 TIFRSParser 封裝、財務比率計算、JSON 匯出等程式碼可參考 Arelle Python API 文件。
批次處理建議
實務上處理 1800 家上市櫃公司的季報需要並行化。可用 concurrent.futures.ProcessPoolExecutor 啟動多進程,每個進程須建立獨立 Cntlr.Cntlr() 實例(Arelle 內部維持 XML 解析器狀態,不適合多執行緒共享)。
幾個生產環境的關鍵考量:
- 記憶體規劃:單一 TIFRS 文件解析峰值約 200–400 MB,8 worker 即達 3 GB;視機器調整
max_workers。 - 錯誤隔離:每檔案以 try/except 包裹,避免單一壞檔終止整批;錯誤摘要記入 warn log。
- Schema 快取:以
--internetConnectivity offline搭配本地 taxonomy 倉庫,省下重複下載 IFRS / TIFRS schema 的時間,整批處理可加速 3–5 倍。
常見問題與解決方案
問題 1:繁體中文顯示亂碼
症狀:解析出的標籤變成 \u8cc7\u7522 之類的 escaped 字串,或在終端機顯示為 ? / 方塊。
根因:Arelle 預設用系統 locale 解析;Windows 環境的 cp950 與 XBRL 內部 UTF-8 不一致時即亂碼。
修法:所有 IO 顯式指定 encoding="utf-8",並在啟動時設置 PYTHONIOENCODING=utf-8;JSON dump 使用 ensure_ascii=False。
問題 2:找不到台灣特定元素
症狀:用 IFRS 名稱(如 Assets)能查到,用 TIFRS 名稱(如 tifrs-bsta:Assets)查不到。
根因:TIFRS 元素掛在 tifrs-bsta / tifrs-cor 等延伸命名空間下,必須以 qualified name 比對,不能只比 localName。
修法:判斷時改用 fact.qname.namespaceURI 結合 localName,並建立國際 ↔ 台灣 element 對應表(IFRS Assets ↔ tifrs-bsta:Assets),方便雙向查詢。
問題 3:計算鏈路驗證失敗
症狀:Arelle 報告「資產 ≠ 負債 + 權益」,但人工核對 PDF 報表是對的。
根因:(1) decimals 屬性未正規化、(2) 跨期間 fact 混在一起計算、(3) 子科目重複計入。
修法:先以同一個 contextRef 過濾,再對每個 fact 套用 decimals 倍數還原,最後用 Arelle 內建 model.modelXbrl.compileCalc() 自動驗證。
問題 4:效能瓶頸
症狀:單檔解析動輒 30 秒以上,1800 家批次跑超過 8 小時。
主要瓶頸:(1) 線上下載 IFRS / TIFRS schema(每檔都連網)、(2) 重複初始化 Cntlr、(3) 全部 fact 一起載入記憶體。
優化方向:(1) --internetConnectivity offline + 本地 schema 快取、(2) 進程池內重用 Cntlr 實例、(3) 對單檔只 load 需要的 linkbase(用 loadOptions={'noCalc': True} 等選項略過不必要的驗證)。
驗證與合規工具
Arelle 命令列驗證
最直接的合規驗證方式是用 Arelle CLI 對照 TIFRS taxonomy 驗證:
# 完整驗證(calc / formula / 公式)
arelleCmdLine --file=tsmc_2024q4.xbrl \
--validate \
--logFile=validation.log
# 只跑必要驗證(生產環境批次掃描用)
arelleCmdLine --file=tsmc_2024q4.xbrl \
--validate \
--internetConnectivity=offline \
--plugins=transforms/SEC,validate/EFM關鍵旗標:
--validate:啟動 XBRL 2.1 + Calculation linkbase 驗證。--internetConnectivity=offline:強制使用本地 taxonomy 快取,速度差 5–10 倍。--plugins:載入額外驗證 plugin,例如 SEC 規則、EFM、或自製 TIFRS 規則。
Python 自動化驗證骨架
對於需要在 CI/CD 流程中自動驗證的場景,建議封裝為以下流程:
- 格式檢查:確認檔案是合法 XBRL 2.1,namespace 與 schema 對齊。
- 計算驗證:資產 = 負債 + 權益、營收 ≥ 0、本期淨利 = 營業 + 業外 - 稅費。
- 必填欄位檢查:上市櫃必填項目(公司名稱、股票代號、會計師簽證等)是否齊全。
- 跨期間一致性:本期期初餘額是否等於上期期末餘額。
任一步失敗即標記檔案進入人工複核佇列;通過則寫入合規證據資料庫(含驗證時間、Arelle 版本、validation log SHA-256)。
工具與資源
推薦開發工具
| 工具 | 類型 | 用途 | 授權 |
|---|---|---|---|
| Arelle | 桌面應用/CLI | XBRL 解析、驗證、視覺化 | Apache 2.0 |
| python-xbrl | Python 套件 | XBRL 處理程式庫 | MIT |
| Altova XMLSpy | 商業軟體 | XML/XBRL 編輯器 | 商業授權 |
| oXygen XML Editor | 商業軟體 | XML/XBRL 開發環境 | 商業授權 |
| XBRL Analyst | Excel 插件 | Excel 中處理 XBRL | 商業授權 |
官方資源連結
重要連結
- 台灣證券交易所 XBRL 專區:https://www.twse.com.tw/xbrl
- 公開資訊觀測站:https://mops.twse.com.tw
- TIFRS 分類標準下載:(需透過證交所 XBRL 專區取得)
- Arelle 官網:https://arelle.org
- XBRL 國際組織:https://www.xbrl.org
Python 開發環境設定
# 建立虛擬環境
python -m venv xbrl_env
source xbrl_env/bin/activate # Linux/Mac
# xbrl_env\Scripts\activate # Windows
# 安裝必要套件
pip install arelle-release
pip install pandas
pip install lxml
pip install openpyxl # 如需 Excel 輸出
# 安裝開發工具
pip install pytest # 測試
pip install black # 程式碼格式化
pip install mypy # 類型檢查
# 建立 requirements.txt
pip freeze > requirements.txt未來發展趨勢
ESG 資訊揭露整合
台灣金管會已規劃將 ESG(環境、社會、公司治理)資訊納入 XBRL 申報範圍。
即時報導(Real-time Reporting)
從季度報導逐步走向即時揭露:
發展階段
| 階段 | 時間框架 | 報導頻率 | 技術要求 |
|---|---|---|---|
| 第一階段(現行) | 2018-2025 | 季報 | 批次上傳 |
| 第二階段 | 2025-2028 | 月報 | API 整合 |
| 第三階段 | 2028-2030 | 即時 | 串流處理 |
| 第四階段 | 2030+ | 交易級 | 區塊鏈驗證 |
API 標準化
未來 API 可能規格
# 假設的未來 TIFRS API
import requests
# 取得公司最新財報
response = requests.get(
'https://api.twse.com.tw/xbrl/v2/company/2330/latest',
headers={'Authorization': 'Bearer YOUR_API_KEY'}
)
financial_data = response.json()
# 訂閱即時更新
from websocket import create_connection
ws = create_connection('wss://api.twse.com.tw/xbrl/v2/stream')
ws.send(json.dumps({
'action': 'subscribe',
'companies': ['2330', '2317'],
'events': ['financial_update', 'material_event']
}))
while True:
result = ws.recv()
data = json.loads(result)
print(f"收到更新: {data['company']} - {data['event']}")結語
台灣 TIFRS 標準雖然基於國際 IFRS 架構,但在命名空間、語言標籤、會計科目和技術實作上都有顯著的在地化特色。對於開發 XBRL 處理系統的技術人員而言,深入理解這些差異是確保系統正確性、穩定性和效能的關鍵。
關鍵要點回顧
- 命名空間差異:TIFRS 使用 tifrs-* 系列命名空間,而非國際的 ifrs-*
- 繁體中文支援:完整的雙語標籤系統,優先使用 zh-TW 標籤
- 股本計算:台灣採用 10 元標準面額,影響股數和每股指標計算
- 貨幣尺度:注意 decimals 屬性的正確處理,常見千元、百萬元單位
- 實體識別:使用公開資訊觀測站的證券代號作為識別碼
最佳實踐建議
- 使用 Arelle 作為基礎 XBRL 處理引擎
- 實作完整的錯誤處理和驗證機制
- 採用快取策略提升批次處理效能
- 建立自動化測試確保資料正確性
- 保持對 TIFRS 標準更新的追蹤
隨著台灣持續推動財報數位化,以及 ESG 揭露、即時報導等新趨勢的發展,TIFRS 標準還會持續演進。掌握這些技術細節和實作要點,將有助於開發出穩健、高效的財報處理系統,為台灣金融科技生態系統貢獻價值。
延伸閱讀
產品解決方案
參考文獻
- XBRL 2.1 Specification - XBRL International
- Inline XBRL 1.1 Specification - XBRL International
- 台灣證券交易所 XBRL 實施指引
- TIFRS 分類標準技術規範
- Arelle 官方文件
標籤: #iXBRL #XBRL #TIFRS #台灣會計準則 #技術規範 #財報標準 #開發指南 #IFRS