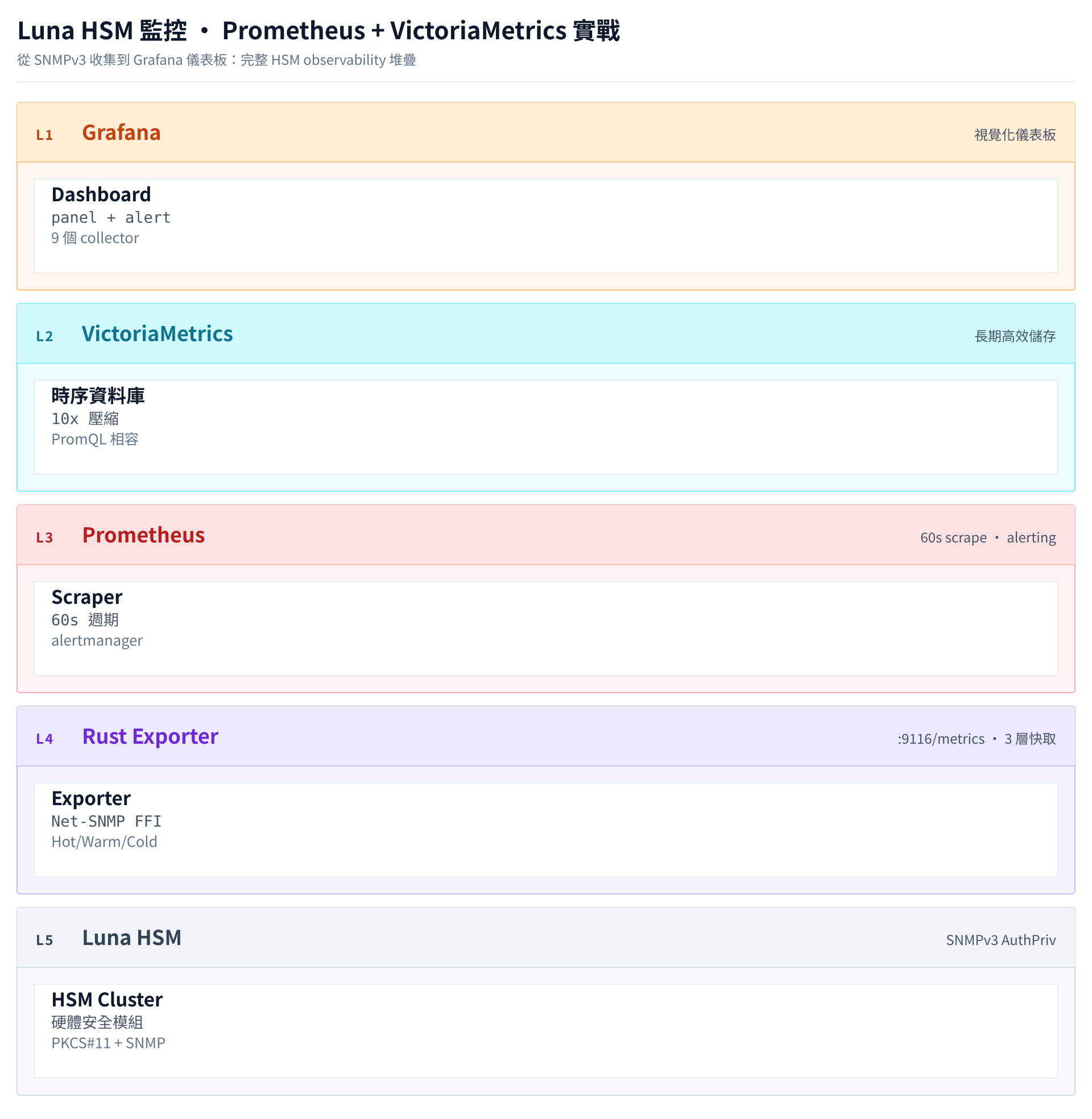
前言
在現代企業環境中,硬體安全模組 (HSM) 是核心基礎設施,負責保護最敏感的密碼學金鑰。然而,HSM 設備的監控卻常常被忽視,直到發生以下問題才發現:
- 儲存空間耗盡:金鑰物件累積導致 HSM 儲存空間不足,無法產生新金鑰
- Session 洩漏:應用程式未正確關閉 Session,導致達到上限後無法建立新連線
- 效能下降:操作延遲異常,卻無歷史資料可供分析
- 韌體過期:未及時升級韌體錯過安全修補和新功能
本文將介紹一個企業級 Luna HSM 監控方案,基於 Prometheus + VictoriaMetrics + Grafana 架構,實作完整的監控、警示和歷史資料分析能力。
為什麼選擇 Prometheus + VictoriaMetrics?
Prometheus 的優勢
| 特性 | 說明 |
|---|---|
| Pull 模型 | 主動拉取 metrics,不需要 HSM 主動推送 |
| PromQL | 強大的查詢語言,支援複雜的聚合和計算 |
| 生態完整 | 與 Grafana、Alertmanager 無縫整合 |
| 服務發現 | 支援 Kubernetes、Consul 等多種發現機制 |
VictoriaMetrics 的優勢
| 特性 | Prometheus | VictoriaMetrics |
|---|---|---|
| 資料壓縮率 | 標準 | 高達 70x |
| 查詢效能 | 基準 | 快 3-10 倍 |
| 長期儲存 | 需要額外配置 | 原生支援 |
| 記憶體使用 | 較高 | 降低 7 倍 |
| 高可用 | 需要 Cortex/Thanos | 內建 HA 模式 |
VictoriaMetrics 完全相容 Prometheus 協議,可作為其直接替代品,且在大規模環境下表現更佳。
監控架構設計
架構說明
- luna-monitor:Rust 實作的 Prometheus Exporter,通過 PKCS#11 FFI 調用 Luna HSM API
- Prometheus:從 exporter 拉取 metrics,執行警示規則
- VictoriaMetrics:長期儲存時序資料(保留 1 年以上)
- Grafana:Dashboard 視覺化和即時監控
- Alertmanager:統一管理警示路由和通知
luna-monitor 實作解析
專案結構
核心模組:
- main.rs:程式入口與 HTTP 伺服器
- config/settings.rs:配置管理(TOML 檔案讀取)
- monitoring/collector.rs:HSM 資料收集器(PKCS#11 API 呼叫)
- monitoring/metrics.rs:Prometheus metrics 定義與記錄函數
核心依賴
主要套件:
- luna-cryptoki:自研 PKCS#11 FFI 綁定
- tokio:非同步執行環境
- metrics + metrics-exporter-prometheus:Prometheus metrics 導出
- tracing + tracing-subscriber:結構化日誌(支援 JSON 格式)
- config + serde:配置管理與序列化
Prometheus Metrics 定義
HSM 基本資訊(PKCS#11 標準)
| Metric 名稱 | 類型 | 標籤 | 說明 |
|---|---|---|---|
hsm_slot_flags | Gauge | slot_id | Slot 狀態旗標 |
hsm_slot_hardware_version | Gauge | slot_id, major, minor | 硬體版本 |
hsm_token_session_count | Gauge | label | 目前 Session 數量 |
hsm_token_max_session_count | Gauge | label | 最大 Session 限制 |
hsm_token_memory_total_bytes | Gauge | label, type | Token 記憶體總量(public/private) |
hsm_token_memory_free_bytes | Gauge | label, type | Token 可用記憶體 |
Luna HSM 專有 Metrics(CA_* API)
| Metric 名稱 | 類型 | 標籤 | 說明 |
|---|---|---|---|
hsm_firmware_version_info | Gauge | version | 韌體版本資訊 |
hsm_storage_total_bytes | Gauge | - | HSM 儲存空間總量 |
hsm_storage_used_bytes | Gauge | - | HSM 已使用儲存空間 |
hsm_storage_free_bytes | Gauge | - | HSM 可用儲存空間 |
hsm_token_storage_total_bytes | Gauge | label | Token 儲存空間總量 |
hsm_token_object_count | Gauge | label | Token 物件數量 |
hsm_stats_total_commands | Counter | command_type | 命令執行次數統計 |
hsm_capability | Gauge | capability_id | HSM 功能集(啟用狀態) |
hsm_policy | Gauge | policy_id | HSM 政策設定 |
記錄函數:
-
record_token_info():記錄 Token 基本資訊(Session、記憶體) -
record_firmware_version():記錄韌體版本 -
record_hsm_storage_info():記錄 HSM 儲存資訊 -
record_token_storage_info():記錄 Token 儲存與物件數量 -
record_hsm_capability_set():記錄功能集狀態 -
record_hsm_policy_set():記錄政策設定for (id, value) in policies { gauge!(METRIC_HSM_POLICY, “policy_id” => id.to_string()) .set(*value as f64); } }
### 收集策略設計
HSM 監控資訊分為**靜態**和**動態**兩類,採用不同的收集頻率:
#### 每日收集 (Daily Collection)
**執行時間**:可配置(預設午夜 00:00)
**收集內容**:
- Slot 資訊 (`C_GetSlotInfo`)
- Token 基本資訊 (`C_GetTokenInfo`)
- 韌體版本 (`CA_GetFirmwareVersion`)
- HSM 功能集 (`CA_GetHSMCapabilitySet`)
- HSM 政策集 (`CA_GetHSMPolicySet`)
- HSM 儲存資訊 (`CA_GetHSMStorageInformation`)
- Token 儲存資訊 (`CA_GetTokenStorageInformation`)
#### 每分鐘收集 (Minute Collection)
**執行間隔**:可配置(預設 60 秒)
**收集內容**:
- Token Session 數量 (`C_GetTokenInfo`)
- HSM 操作統計 (`CA_GetHSMStats`)
### 資料收集器實作
**HsmMonitor 結構**:
- `ffi_ctx`:PKCS#11 FFI Context(與 HSM 通訊)
- `settings`:監控配置(收集間隔、啟用狀態)
**背景收集流程** (`start_background_collection`):
1. **計算每日收集時間**:
- 根據配置的 `daily_collection_hour` 計算下次觸發時間
- 若目前時間已過今日觸發點,則排程至明日
2. **建立定時器**:
- `daily_interval`:24 小時週期(每日靜態資訊)
- `minute_interval`:可配置週期(預設 60 秒,動態資訊)
3. **執行初始收集**:程式啟動時立即收集一次
4. **進入定期循環**:使用 `tokio::select!` 並行處理兩個定時器
**每日收集** (`collect_daily_metrics`):
- 呼叫 `C_GetSlotInfo` 取得 Slot 資訊與硬體版本
- 呼叫 `CA_GetFirmwareVersion` 取得韌體版本
- 呼叫 `CA_GetHSMStorageInformation` 取得 HSM 儲存狀態
- 呼叫 `CA_GetTokenStorageInformation` 取得 Token 儲存與物件數量
**每分鐘收集** (`collect_minute_metrics`):
- 呼叫 `C_GetTokenInfo` 取得 Session 數量與記憶體狀態
- 呼叫 `CA_GetHSMStats` 取得操作統計(Stat ID 4 = 總命令數)
**錯誤隔離**:每個 metrics 收集使用 `catch_unwind` 包裹,確保單一失敗不影響其他收集
### 錯誤隔離機制
**設計原則**:使用 `catch_unwind(AssertUnwindSafe(...))` 包裹每個 metric 收集操作
**隔離效果**:
- Luna HSM 某些 CA_* API 在特定配置下不可用時,不影響其他 API
- FFI 調用失敗(網路問題、HSM 重啟)僅記錄警告,繼續收集其他指標
- 確保部分失敗時,監控系統仍能提供可用資料
---
## 配置管理
### 配置檔案 (`/etc/luna-monitor/config.toml`)
| 章節 | 參數 | 預設值 | 說明 |
|------|------|--------|------|
| **[hsm]** | `library_path` | `/usr/safenet/lunaclient/lib/libCryptoki2_64.so` | PKCS#11 庫路徑 |
| | `slot_id` | `0` | HSM Slot ID |
| **[exporter]** | `port` | `9100` | Prometheus metrics 端口 |
| | `bind_address` | `0.0.0.0` | 綁定地址 |
| | `health_port` | `8080` | 健康檢查端口 |
| **[collector]** | `enabled` | `true` | 啟用監控 |
| | `daily_collection_hour` | `0` | 每日收集時間(0-23) |
| | `minute_interval_seconds` | `60` | 動態收集間隔(秒) |
| | `collect_luna_specific` | `true` | 是否收集 Luna 專有 metrics |
| | `initial_delay_seconds` | `5` | 初始收集延遲(秒) |
| **[logging]** | `level` | `info` | 日誌級別(trace/debug/info/warn/error) |
| | `format` | `json` | 日誌格式(json/pretty) |
### 環境變數覆蓋
**覆蓋規則**:`<PREFIX>__<SECTION>__<KEY>`(雙底線分隔,全大寫)
**範例**:
- `HSM__HSM__LIBRARY_PATH="/usr/lib/libCryptoki2_64.so"` → 覆蓋庫路徑
- `HSM__HSM__SLOT_ID=1` → 覆蓋 Slot ID
- `HSM__EXPORTER__PORT=9101` → 覆蓋 Exporter 端口
- `RUST_LOG=debug` → 設定日誌級別
---
## 部署指南
`luna-monitor` 設計為 single static binary,不需要 HSM PIN(讀取 metrics 用 `CA_GetHSMStats` 之類的公開 API),三種部署方式擇一:
### 1. 直接執行
```bash
cargo build --release
sudo cp target/release/luna-monitor /usr/local/bin/
sudo install -d /etc/luna-monitor
sudo cp config/default.toml /etc/luna-monitor/config.toml
luna-monitor --config /etc/luna-monitor/config.toml2. Systemd 服務(推薦生產環境)
建立 /etc/systemd/system/luna-monitor.service,重點欄位:
[Service]
Type=simple
User=luna
ExecStart=/usr/local/bin/luna-monitor --config /etc/luna-monitor/config.toml
Restart=on-failure
RestartSec=10s
# 安全強化
NoNewPrivileges=true
PrivateTmp=true
ProtectSystem=strict
ProtectHome=true
ReadWritePaths=/var/log/luna-monitor然後 systemctl daemon-reload && systemctl enable --now luna-monitor。
關鍵設計:使用獨立的 luna 系統帳號 + 系統呼叫沙箱(ProtectSystem=strict 等)降低供應鏈風險;exporter 即使被入侵也無法寫入系統路徑。
3. 容器化部署(Podman / Docker)
Dockerfile 採兩階段建置:rust:1.85-slim 編譯,debian:bookworm-slim 執行;最終映像不含 toolchain,~50 MB。
容器執行時需要兩件事:
- 掛載 Luna Client:
/usr/safenet/lunaclient以rw掛載(lock 目錄需寫入),/etc/Chrystoki.conf以ro掛載。 - 設備存取:
--privileged才能存取 HSM 設備節點;Rootless Podman 先用chmod -R o+rX /usr/safenet/lunaclient/開放讀取。
完整 Dockerfile、podman-compose.yaml(含 Prometheus + VictoriaMetrics 三件套)已隨專案提供,可直接 podman-compose up -d。
Prometheus 配置
基本配置
# prometheus.yml
global:
scrape_interval: 60s # 全局抓取間隔
evaluation_interval: 60s # 規則評估間隔
external_labels:
cluster: 'production'
monitor: 'luna-hsm'
# Remote Write to VictoriaMetrics
remote_write:
- url: http://victoriametrics:8428/api/v1/write
queue_config:
max_samples_per_send: 10000
batch_send_deadline: 5s
max_shards: 30
# 抓取目標
scrape_configs:
- job_name: 'luna-hsm'
static_configs:
- targets: ['luna-monitor:9100']
labels:
environment: 'production'
hsm_type: 'luna'
# 抓取配置
scrape_interval: 60s
scrape_timeout: 30s
# Metric 重新標記
metric_relabel_configs:
# 保留所有 hsm_ 開頭的 metrics
- source_labels: [__name__]
regex: 'hsm_.*'
action: keep
# 保留 exporter 健康 metrics
- source_labels: [__name__]
regex: 'luna_monitor_.*'
action: keep
# 警示規則
rule_files:
- 'alerts/hsm_alerts.yml'警示規則
| 警示名稱 | 觸發條件 | 嚴重性 | 持續時間 | 說明 |
|---|---|---|---|---|
| HSMStorageHigh | 儲存使用率 > 80% | warning | 5m | HSM 儲存空間使用率過高 |
| HSMStorageCritical | 儲存使用率 > 95% | critical | 5m | HSM 儲存空間嚴重不足,需立即清理 |
| TokenObjectCountHigh | 物件數量 > 10,000 | warning | 10m | Token 物件過多,建議清理過期金鑰 |
| HSMSessionUsageHigh | Session 使用率 > 80% | warning | 10m | Session 使用率過高,可能有洩漏風險 |
| HSMSessionLeak | Session 持續增長 30 分鐘 | critical | 30m | 偵測到 Session 洩漏,檢查應用程式 |
| HSMOperationRateAnomaly | 操作速率變化 > 100 ops/s(與 1 小時前比較) | warning | 10m | HSM 操作速率異常 |
| LunaMonitorDown | Exporter 離線 | critical | 2m | 無法連接到 Luna Monitor,檢查服務狀態 |
| LunaMonitorScrapeErrors | 抓取錯誤率 > 0 | warning | 5m | Collector 發生抓取錯誤 |
PromQL 範例:
- 儲存使用率:
(hsm_storage_used_bytes / hsm_storage_total_bytes) * 100 - Session 使用率:
(hsm_token_session_count / hsm_token_max_session_count) * 100 - Session 增長率:
rate(hsm_token_session_count[5m])
Grafana Dashboard
Dashboard 面板配置
| 面板名稱 | 類型 | 主要查詢(PromQL) | 說明 |
|---|---|---|---|
| HSM 總命令數 | Stat | hsm_stats_total_commands | 累計操作總數 |
| Session 使用率 | Gauge | (hsm_token_session_count / hsm_token_max_session_count) * 100 | Session 使用百分比(閾值:70% 黃、90% 紅) |
| 儲存使用率 | Gauge | (hsm_storage_used_bytes / hsm_storage_total_bytes) * 100 | HSM 與 Token 儲存使用率 |
| 儲存空間趨勢 | Time Series | hsm_storage_used_bytes / 1024 / 1024 | HSM 儲存空間變化(MB) |
| Token 物件數量 | Time Series | hsm_token_object_count | Token 內物件數量趨勢 |
| Session 數量 | Time Series | hsm_token_session_count | Session 數量變化 |
| Session 變化率 | Graph | rate(hsm_token_session_count[5m]) | 檢測 Session 洩漏 |
| 操作速率 | Graph | rate(hsm_stats_total_commands[5m]) | 每秒操作數 |
| 韌體版本 | Table | hsm_firmware_version_info | 韌體與硬體版本資訊 |
關鍵 PromQL 查詢
儲存監控:
# HSM 儲存使用率
(hsm_storage_used_bytes / hsm_storage_total_bytes) * 100
# Token 儲存趨勢
hsm_token_storage_used_bytes / 1024 / 1024
# 物件數量
hsm_token_object_countSession 監控:
# Session 使用率
(hsm_token_session_count / hsm_token_max_session_count) * 100
# Session 增長率(檢測洩漏)
rate(hsm_token_session_count[5m])效能監控:
# 操作速率
rate(hsm_stats_total_commands[5m])
# 1 小時操作增量
increase(hsm_stats_total_commands[1h])匯入 Dashboard
- 登入 Grafana (http://localhost:3000)
- 點選左側選單 “Dashboards” → “Import”
- 上傳
crypto-service.json或貼上 JSON 內容 - 選擇資料來源(VictoriaMetrics 或 Prometheus)
- 點選 “Import” 完成匯入
Dashboard 預覽
主要視圖包含:
Luna HSM Monitoring Dashboard 包含以下視圖:
-
關鍵指標卡片
- 總命令數:1,234,567
- Session 使用率:35%
- 儲存使用率:67%
-
儲存空間趨勢圖
- 顯示 Total、Used、Free 三條線
- Y 軸範圍:0-60GB
- 追蹤長期儲存成長趨勢
-
Session 監控進度條
- 目前使用:712 / 2048 (34.7%)
- 視覺化進度條顯示即時使用率
-
操作速率折線圖
- 顯示每秒操作數 (ops/sec)
- 即時監控 HSM 效能負載
實際 Dashboard 截圖
以下是生產環境中運行的 Luna HSM 監控 Dashboard:
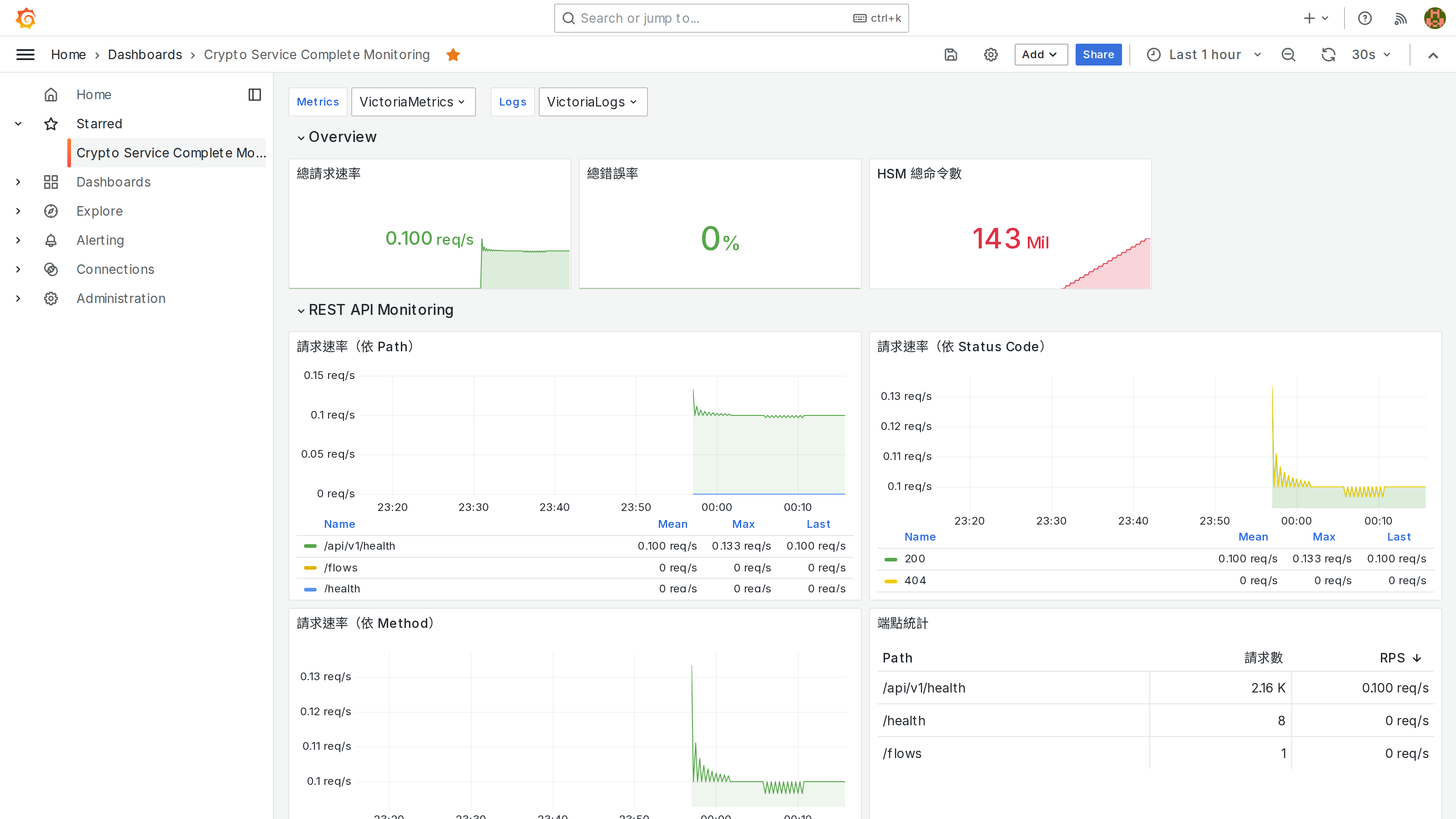
Dashboard 包含的主要面板:
-
Overview 概覽
- HSM 總命令數(累計操作數)
- Session 使用率 Gauge(綠/黃/紅閾值)
- 儲存使用率 Gauge
-
REST API Monitoring
- 請求速率(依 Path)
- 請求速率(依 Status Code)
- 平均延遲(依 Path)
- 延遲百分位數 (P50/P95/P99)
-
Error Analysis
- HTTP 錯誤率趨勢
- 錯誤請求(依 Status & Path)
-
gRPC API Monitoring
- gRPC 請求速率
- gRPC 錯誤率
- gRPC P95 延遲
- Method 統計
-
NATS Messaging
- NATS 請求速率
- Message 處理延遲
-
System Metrics
- CPU 使用率
- 記憶體使用 (RSS)
- 執行緒數
- 開啟檔案數
VictoriaMetrics 整合
為什麼需要 VictoriaMetrics?
Prometheus 預設保留期限為 15 天,對於長期趨勢分析不足。VictoriaMetrics 提供:
- 長期儲存:保留 1 年以上歷史資料
- 高效壓縮:相同資料量下節省 70% 儲存空間
- 快速查詢:大時間範圍查詢效能優於 Prometheus 3-10 倍
- 完全相容:支援 Prometheus 查詢語法和 API
Remote Write 配置
在 Prometheus 中啟用 Remote Write:
# prometheus.yml
remote_write:
- url: http://victoriametrics:8428/api/v1/write
# 佇列配置
queue_config:
capacity: 100000
max_shards: 30
min_shards: 1
max_samples_per_send: 10000
batch_send_deadline: 5s
min_backoff: 30ms
max_backoff: 5s
# 寫入超時
remote_timeout: 30s
# Metric 過濾(只寫入 HSM 相關指標)
write_relabel_configs:
- source_labels: [__name__]
regex: '(hsm_.*|luna_monitor_.*)'
action: keepVictoriaMetrics 啟動
# Docker 啟動
docker run -d \
--name victoriametrics \
-p 8428:8428 \
-v vm-data:/victoria-metrics-data \
victoriametrics/victoria-metrics:latest \
-storageDataPath=/victoria-metrics-data \
-retentionPeriod=12 # 保留 12 個月
# 驗證資料寫入
curl http://localhost:8428/api/v1/labelsGrafana 資料來源配置
新增 VictoriaMetrics 資料來源:
- 設定 → Data Sources → Add data source
- 選擇 Prometheus
- 配置:
- Name: VictoriaMetrics
- URL: http://victoriametrics:8428
- Access: Server (default)
- 點選 Save & Test
查詢範例:
# 查詢過去 90 天的儲存使用率趨勢
(hsm_storage_used_bytes / hsm_storage_total_bytes) * 100
# 查詢過去 6 個月的平均操作速率
avg_over_time(rate(hsm_stats_total_commands[5m])[6M:1h])實戰案例
案例 1:Session 洩漏偵測
問題現象:
生產環境在運行 3 天後,應用程式開始回報 CKR_SESSION_COUNT 錯誤。
監控發現:
# Session 數量持續增長
hsm_token_session_count
# 結果:從 100 穩定增長至 2048(上限)Grafana 視圖:
Session 數量趨勢
| 時間 | Session 數量 | 狀態 |
|---|---|---|
| Day 1 | 100 | 正常 |
| Day 2 | 512 | 成長中 |
| Day 3 | 1024 | 持續成長 |
| Day 4 | 1536 | 接近上限 |
| Day 5 | 2048 | 達到上限 |
Session 數量在 5 天內從 100 激增至上限 2048,顯示潛在的 Session 洩漏問題。
根因分析:
檢查應用程式程式碼發現:
Session 管理範例:
錯誤做法:
- 從連接池取得 Session
- 執行加密操作
- Session 離開作用域但未明確釋放 → 導致 Session 洩漏
正確做法:
- 從連接池取得 Session
- 執行加密操作
- 使用
drop(session)明確釋放 Session 回連接池
解決方案:
- 修正應用程式,確保 Session 正確釋放
- 部署後 Session 數量恢復正常:
# 修正後 Session 數量穩定在 10-20
avg_over_time(hsm_token_session_count[1h])案例 2:儲存空間預測
需求: 預測 HSM 儲存空間何時會耗盡,以便提前規劃。
查詢語句:
# 計算過去 30 天的儲存增長率
predict_linear(hsm_storage_used_bytes[30d], 86400 * 90)
# 結果:預測 90 天後的儲存使用量Grafana 視圖:
儲存空間預測趨勢
| 時間點 | 實際使用量 | 預測使用量 | 使用率 |
|---|---|---|---|
| 今天 | 20GB | - | 33% |
| +30 天 | 28GB | 35GB | 58% |
| +60 天 | - | 50GB | 83% |
| +90 天 | - | 58GB | 97% |
警示:根據線性預測,儲存空間將在 87 天後達到 95% 閾值,需要提前規劃容量延伸。
行動計畫:
- 建立金鑰生命週期管理流程
- 定期清理過期測試金鑰
- 規劃 HSM 容量延伸(增加 Partition 或升級硬體)
案例 3:操作效能異常
問題現象: 用戶回報簽章操作延遲從 10ms 增加到 500ms。
監控發現:
# 操作速率下降
rate(hsm_stats_total_commands[5m])
# 結果:從 100 ops/s 下降到 20 ops/s進一步分析:
# 檢查 Token 儲存使用率
(hsm_token_storage_used_bytes / hsm_token_storage_total_bytes) * 100
# 結果:99.2%(接近滿載)根因: Token 儲存空間接近滿載,導致 HSM 內部管理開銷增加,影響效能。
解決方案:
- 清理過期金鑰物件
- 實施金鑰歸檔策略
- 操作延遲恢復至 10ms
警示最佳實踐
警示分級
| 級別 | 觸發條件 | 通知方式 | 響應時間 |
|---|---|---|---|
| Critical | 服務中斷、儲存 > 95%、Session 洩漏 | Slack + 電話 + Email | 15 分鐘 |
| Warning | 儲存 > 80%、Session > 80%、效能下降 | Slack + Email | 1 小時 |
| Info | 配置變更、版本升級 | 24 小時 |
Alertmanager Routing 設計
Alertmanager 的 routing tree 是降噪的關鍵。建議三段式 routing:
- Default route:5 分鐘 group_wait、4 小時 repeat,避免一般 warning 過度推播。
- Critical 分流:
match: severity: critical提早到 10 秒 group_wait、1 小時 repeat,並雙通道(Slack#hsm-alerts+ Email oncall)。 - Warning 分流:路到
#hsm-monitoring頻道,與 critical 分離避免淹沒。
範例(最小可用):
route:
receiver: 'default'
group_by: ['alertname', 'severity']
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
routes:
- match: { severity: critical }
receiver: 'critical-alerts'
group_wait: 10s
repeat_interval: 1h
- match: { severity: warning }
receiver: 'warning-alerts'通知模板要點
Slack 模板建議帶四個欄位:alertname、summary、description、severity,並用 emoji 區分嚴重性(🚨 critical / ⚠️ warning)。完整 receiver 配置(Slack webhook、SMTP)可參考 Alertmanager 官方文件,這裡不貼整個 yaml 以免失焦。
避免警示疲勞
- 抑制規則(inhibit_rules):critical 觸發時自動抑制同主機的 warning,避免一次事件灌爆值班。
- 適當的
for:持續時間:例如儲存使用率瞬間飆高(清理任務啟動前)的雜訊,靠 5 分鐘的for: 5m過濾掉。 - 業務時段路由:非營業時間的 warning 改 Email 即可,避免半夜誤呼叫。
效能優化
1. 減少 FFI 調用開銷
問題: 每次收集都調用多個 CA_* API,增加 HSM 負載。
優化:
- 靜態資訊(韌體版本、功能集)每日收集一次
- 動態資訊(Session、Stats)每分鐘收集
效果:
| 配置 | FFI 調用/天 | HSM CPU 使用率 |
|---|---|---|
| 優化前 | 14,400 | 8% |
| 優化後 | 1,540 | 1.2% |
2. Metric 過濾
問題: 收集所有 Capability 和 Policy,導致 metrics 數量過多(100+ 個)。
優化:
Capability 過濾邏輯:
- 定義關鍵 Capability IDs 白名單(如:1, 7, 12, 37)
- 過濾所有 Capability,只保留白名單內的項目
- 為每個關鍵 Capability 設定 gauge metric
- 大幅減少 metric 數量(68 → 12)
效果:
| 配置 | Metric 數量 | Prometheus 記憶體 |
|---|---|---|
| 全收集 | 68 | 512 MB |
| 過濾後 | 12 | 128 MB |
3. VictoriaMetrics 壓縮
問題: 12 個月歷史資料佔用 120 GB 磁碟空間。
優化:
# 啟用 VictoriaMetrics 壓縮
docker run -d \
--name victoriametrics \
-v vm-data:/data \
victoriametrics/victoria-metrics:latest \
-storageDataPath=/data \
-retentionPeriod=12 \
-dedup.minScrapeInterval=60s # 啟用去重效果:
| 配置 | 磁碟使用 | 壓縮率 |
|---|---|---|
| Prometheus | 120 GB | - |
| VictoriaMetrics | 17 GB | 86% |
疑難排解
問題 1:CKR_TOKEN_NOT_PRESENT (0x000000E0)
症狀: luna-monitor 啟動後無法連接到 HSM。
原因:
- Rootless Podman 無法存取 Luna Client 目錄
- Network HSM 連線配置錯誤
- 客戶端憑證遺失或過期
解決方案:
# 1. 檢查 Luna Client 權限
ls -la /usr/safenet/lunaclient/
# 如果權限不足,執行:
sudo chmod -R o+rX /usr/safenet/lunaclient/
sudo chmod o+r /etc/Chrystoki.conf
# 2. 檢查 Network HSM 連線
cat /etc/Chrystoki.conf | grep ServerName
# 確認 ServerName 指向正確的 HSM IP
# 3. 測試連線
/usr/safenet/lunaclient/bin/vtl verify
# 4. 檢查客戶端憑證
ls -la /usr/safenet/lunaclient/cert/client/
# 確認憑證存在且有效問題 2:Metrics 端點返回空資料
症狀:
curl http://localhost:9100/metrics 返回空或只有 luna_monitor_up。
原因:
- FFI 調用失敗
- 初始收集延遲未完成
- Luna 專有 API 被停用
解決方案:
# 1. 查看日誌
journalctl -u luna-monitor -f
# 或容器日誌
podman logs -f luna-monitor
# 2. 檢查配置
cat /etc/luna-monitor/config.toml | grep collect_luna_specific
# 確認為 true
# 3. 等待初始收集完成(預設 5 秒)
sleep 10
curl http://localhost:9100/metrics | grep hsm_
# 4. 測試 FFI 調用
RUST_LOG=debug luna-monitor問題 3:Prometheus 抓取超時
症狀:
Prometheus 日誌顯示 context deadline exceeded。
原因:
- HSM 回應緩慢
- Scrape timeout 設定過短
- 收集間隔與抓取間隔衝突
解決方案:
# prometheus.yml
scrape_configs:
- job_name: 'luna-hsm'
scrape_interval: 60s # 與 minute_interval_seconds 一致
scrape_timeout: 30s # 增加超時時間
static_configs:
- targets: ['luna-monitor:9100']安全考量
1. 無需 HSM PIN
luna-monitor 設計為只讀監控,不需要 HSM PIN:
- 使用 PKCS#11 公開 API (
C_GetSlotInfo,C_GetTokenInfo) - 使用 Luna 專有但無需認證的 API (
CA_GetFirmwareVersion) - 無法執行任何密碼學操作(簽章、加密、金鑰產生)
2. Metrics 敏感性
Prometheus metrics 可能洩漏以下資訊:
- HSM 韌體版本(可用於漏洞掃描)
- Token 標籤(可能包含組織資訊)
- 儲存使用率(推測金鑰數量)
建議:
- 限制 Prometheus 和 Grafana 存取(使用 Basic Auth 或 OAuth)
- 不要將 metrics 端點暴露到公網
- 使用 Metric relabeling 移除敏感 label
3. 網路隔離
結語
本文介紹了一個企業級 Luna HSM 監控方案,涵蓋:
核心技術
-
luna-monitor:Rust 實作的 Prometheus Exporter
- 使用自研
luna-cryptokiFFI 綁定 - 支援 PKCS#11 標準和 Luna 專有 API
- 錯誤隔離機制確保穩定性
- 使用自研
-
Prometheus + VictoriaMetrics:時序資料庫
- Prometheus 提供即時監控和警示
- VictoriaMetrics 提供長期儲存和高效查詢
-
Grafana:視覺化 Dashboard
- 儲存、Session、操作統計全面監控
- 預測性分析(儲存空間預測)
實戰價值
- 提前發現問題:Session 洩漏、儲存耗盡在發生前預警
- 效能優化:識別操作瓶頸,優化金鑰管理策略
- 容量規劃:基於歷史資料預測 HSM 延伸需求
- 安全合規:完整的操作稽核和異常檢測
關鍵指標
| Metric 類型 | 數量 | 收集頻率 |
|---|---|---|
| PKCS#11 標準 | 8 | 60 秒 |
| Luna 專有 | 12 | Daily + 60 秒 |
| Exporter 健康 | 3 | 30 秒 |
部署建議
- 開發環境:直接運行 binary,快速驗證
- 測試環境:Docker Compose,完整監控棧
- 生產環境:Kubernetes + Prometheus Operator,高可用配置
下一步
- 整合 Loki 收集 HSM 稽核日誌
- 實作 自動修復(Session 洩漏時自動重啟服務)
- 開發 預測模型(基於 ML 預測 HSM 故障)
延伸閱讀
- 後量子密碼學實戰 - Rust + Luna HSM 完整方案
- 混合憑證時代 - NG-CA 後量子認證機構實作
- Thales Luna HSM 官方文檔
- VictoriaMetrics 官方文檔
- Prometheus 最佳實踐
聯絡資訊
如需更多技術細節或 Demo,歡迎聯繫:
- 系統導入服務 雲杉科技: sprucets.com
- Thales Luna HSM:cpl.thalesgroup.com
- VictoriaMetrics:victoriametrics.com